
本周四,人工智能托管平台Hugging Face的人工智能模型列表首次突破100 万个,这标志着快速扩张的机器学习领域的一个里程碑。 人工智能模型是一种计算机程序(通常使用神经网络),通过数据训练来执行特定任务或进行预测。 该平台在2016年以聊天机器人应用程序起步,在2020年转向成为人工智能模型的开源中心,现在为开发人员和研究人员提供了大量工具。


机器学习领域所代表的世界远不止像 ChatGPT 这样的大型语言模型(LLM)。 Hugging Face 首席执行官克莱门特-德朗格(Clément Delangue)在 X 上发表的一篇文章中谈到了他的公司如何托管了许多著名的人工智能模型,如”Llama、Gemma、Phi、Flux、Mistral、Starcoder、Qwen、Stable diffusion、Grok、Whisper、Olmo、Command、Zephyr、OpenELM、Jamba、Yi”,而且还有”999984 个其他模型”。
Delangue说,原因在于定制。”他写道:”与’一个模型统治所有模型’的谬论相反,针对你的用例、你的领域、你的语言、你的硬件以及你的一般限制条件而定制的小型专门优化模型会更好。 事实上,很少有人意识到,’拥抱脸谱’上几乎有同样多的模型只对一个组织开放,供公司私下构建人工智能,专门用于他们的用例。
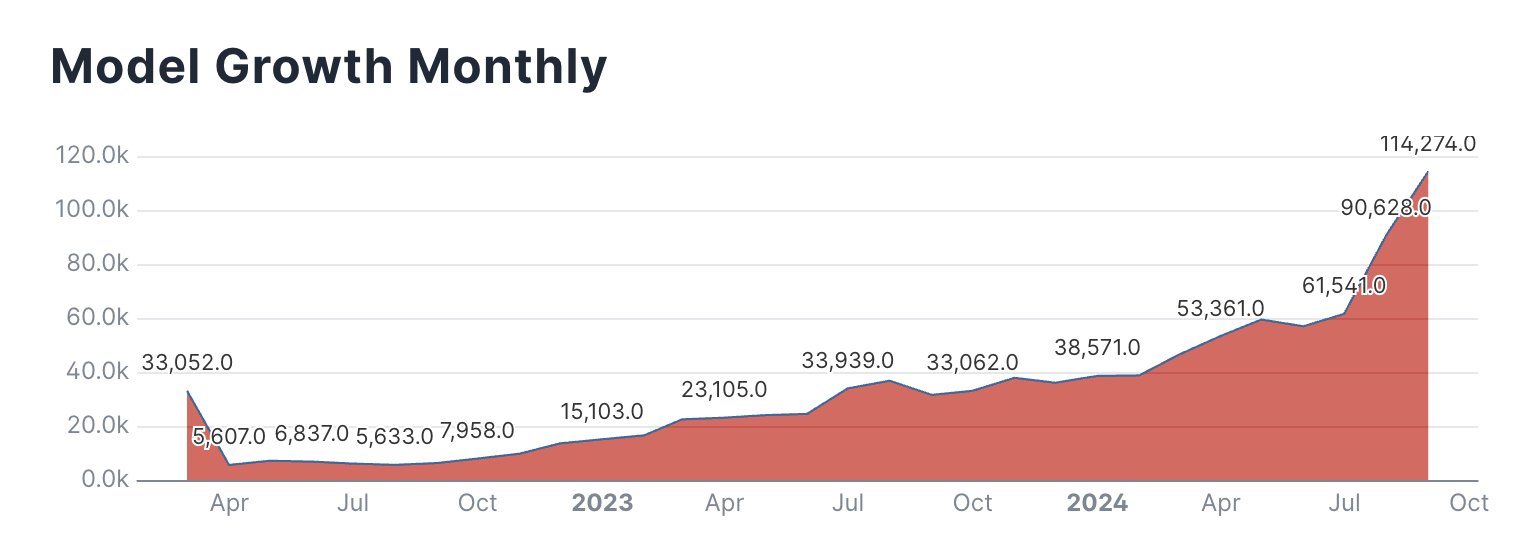
由 Hugging Face 提供的图表显示了随着时间推移逐月添加到 Hugging Face 的人工智能模型数量。
随着整个科技行业人工智能研发步伐的加快,Hugging Face 已转型成为一个重要的人工智能平台。 短短几年间,随着人们对这一领域的兴趣日益浓厚,网站上托管的模型数量也急剧增加。 在 X 上,Hugging Face 产品工程师 Caleb Fahlgren 张贴了一张平台上每月创建的模型图表(以及一个指向其他图表的 链接),他说:”模型逐月呈指数增长,而九月还没有结束。
微调的力量
正如德朗格在上文所暗示的,平台上的模型数量之多源于平台的协作性质以及针对特定任务对现有模型进行微调的做法。 微调是指对现有模型进行额外训练,为其神经网络添加新概念,并改变其产生输出的方式。 世界各地的开发人员和研究人员都在贡献自己的成果,从而形成了一个庞大的生态系统。
例如,该平台上有许多不同的 Meta 开放权重 Lama 模型,它们代表了原始基础模型的不同微调版本,每个版本都针对特定应用进行了优化。
Hugging Face 的资源库包含适用于各种任务的模型。 浏览其模型页面,可以在”多模态”部分看到图像到文本、视觉问题解答和文档问题解答等类别。 在”计算机视觉”类别中,有深度估计、对象检测和图像生成等子类别。 自然语言处理任务(如文本分类和问题解答)以及音频、表格和强化学习(RL)模型也有体现。
放大/ 2024 年 9 月 26 日拍摄的拥抱脸模型页面截图。
如果按”下载次数最多”排序,Hugging Face 模型列表揭示了人们认为哪些人工智能模型最有用的趋势。 排名第一的是麻省理工学院的音频谱图转换器,其下载量高达 1.63 亿次,遥遥领先,该模型可对语音、音乐和环境声音等音频内容进行分类。 紧随其后的是Google的BERT,其下载量为 5420 万次,这是一个人工智能语言模型,通过预测遮蔽的单词和句子关系来学习理解英语,使其能够协助完成各种语言任务。
排在前五位的人工智能模型是all-MiniLM-L6-v2(该模型将句子和段落映射为 384 维密集向量表示,适用于语义搜索)、 Vision Transformer(将图像处理为补丁序列,以执行图像分类),以及 OpenAI 的CLIP(连接图像和文本,允许使用自然语言对视觉内容进行分类或描述)。
不管是什么模型或任务,该平台都在不断发展壮大。Delangue 写道:”如今,HF 上每 10 秒钟就会创建一个新的存储库(模型、数据集或空间)。”最终,模型的数量将和代码库的数量一样多,我们将为此而努力!”
文章《房小蜂》为互联网资源,版权归原作者所有,发布者:房小蜂,转转请注明出处:https://www.fangxiaofeng.com/hot/5320.html
